Unified Search has been introduced in eXo Platform 4 that greatly improves search capabilities. All resources of the whole site (content, files, wiki pages, and more) can now be easily found from a single and centralized location. Besides these out-of-the-box capabilities, a new API allows creating custom search connectors to extend the search scope and enrich results.
This section explains how to implement and configure the search connector to fetch data from an external resource, for example Wikipedia. This search connector will retrieve data indexed by ElasticSearch - highly powerful and easy to use the search engine. You can decide what your search connector returns (data indexed by another search engine, data from a database and other custom data stored in eXo, and more).
Download ElasticSearch, then extract and start ElasticSearch with the command below:
Linux: bin/elasticsearch -f
Windows: bin/elasticsearch or bin/elasticsearch.bat
Index data in ElasticSearch.
ElasticSearch has no indexed data, so you need to feed it. For this purpose, you will use the Wikipedia River plugin. (River is an ElasticSearch component which feeds ElasticSearch with data to index). The Wikipedia River plugin simply feeds ElasticSearch with Wikipedia pages.
i. Stop the ElasticSearch server, then install the Wikipedia River plugin with:
Linux: bin/plugin -install elasticsearch/elasticsearch-river-wikipedia/1.3.0
Windows: bin/plugin --install elasticsearch/elasticsearch-river-wikipedia/1.3.0
ii. Restart the ElasticSearch server. You should see logs similar to the following:
[2013-11-27 11:55:48,716][INFO ][node] [It, the Living Colossus] version[0.90.7], pid[14776], build[36897d0/2013-11-13T12:06:54Z] [2013-11-27 11:55:48,716][INFO ][node] [It, the Living Colossus] initializing ... [2013-11-27 11:55:48,725][INFO ][plugins] [It, the Living Colossus] loaded [river-wikipedia], sites [] [2013-11-27 11:55:50,632][INFO ][node] [It, the Living Colossus] initialized [2013-11-27 11:55:50,632][INFO ][node] [It, the Living Colossus] starting ... [2013-11-27 11:55:50,718][INFO ][transport] [It, the Living Colossus] bound_address {inet[/0:0:0:0:0:0:0:0:9300]}, publish_address {inet[/192.168.0.5:9300]}This ensures that the Wikipedia River plugin is correctly installed: loaded [river-wikipedia].
iii. Start indexing Wikipedia pages in ElasticSearch by creating the river with a REST call (curl is used here but you are free to select your favorite tool):
curl -XPUT localhost:9200/_river/my_river/_meta -d ' { "type" : "wikipedia" } 'Note
Fetching data from Wikipedia takes a while, depending on your connection, so don't be panic.
A lot of data is now being indexed by ElasticSearch. You can check this by executing a search with curl -XGET 'http://localhost:9200/_search?q=test'.
The Wikipedia River will index a lot of data. For testing, you should stop the river after a few minutes to avoid filling your entire disk space. This can be done by deleting the river with curl -XDELETE localhost:9200/_river/my_river.
Implement ElasticSearchConnector.
Search connector is a simple class that extends
org.exoplatform.commons.api.search.SearchServiceConnectorand implements the search method:package org.exoplatform.search.elasticsearch;
import ...
public class ElasticSearchConnector extends SearchServiceConnector {
public ElasticSearchConnector(InitParams initParams) {
super(initParams);
}
@Override
public Collection<SearchResult> search(SearchContext context, String query, Collection<String> sites, int offset, int limit, String sort, String order) {
// Fetch data
}
}It needs to be declared in the eXo configuration, either in your extension or directly in the jar which will contain the connector class. Here, the jar method will be used for example:
Add the class in your jar.
Add a file named
configuration.xmltoconf/portalin your jar with the following content (the "type" tag contains the FQN of the connector class):<configuration
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.exoplatform.org/xml/ns/kernel_1_2.xsd http://www.exoplatform.org/xml/ns/kernel_1_2.xsd"
xmlns="http://www.exoplatform.org/xml/ns/kernel_1_2.xsd">
<external-component-plugins>
<target-component>org.exoplatform.commons.api.search.SearchService</target-component>
<component-plugin>
<name>ElasticSearchConnector</name>
<set-method>addConnector</set-method>
<type>org.exoplatform.search.elasticsearch.ElasticSearchConnector</type>
<description>ElasticSearch Connector</description>
<init-params>
<properties-param>
<name>constructor.params</name>
<property name="searchType" value="wikipedia"/>
<property name="displayName" value="Wikipedia"/>
</properties-param>
</init-params>
</component-plugin>
</external-component-plugins>
</configuration>
You now have the skeleton of the search connector.
Fetch results from ElasticSearch.
You need to call ElasticSearch to fetch Wikipedia pages based on the input parameters of the search (query text, offset, limit, sort field, sort order). ElasticSearch provides a Java Client API (TransportClient). This depends on the Lucene artifacts. Since eXo Platform already embeds the Lucene artifacts that are not necessary in the same version as the ones needed by ElasticSearch, conflicts may happen. Instead eXo will directly use the REST API:
package org.exoplatform.search.elasticsearch;
import org.apache.commons.io.IOUtils;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.DefaultHttpClient;
import org.exoplatform.commons.api.search.SearchServiceConnector;
import org.exoplatform.commons.api.search.data.SearchContext;
import org.exoplatform.commons.api.search.data.SearchResult;
import org.exoplatform.container.xml.InitParams;
import org.json.simple.JSONArray;
import org.json.simple.JSONObject;
import org.json.simple.parser.JSONParser;
import java.io.StringWriter;
import java.util.*;
public class ElasticSearchConnector extends SearchServiceConnector {
private Map<String, String> sortMapping = new HashMap<String, String>();
public ElasticSearchConnector(InitParams initParams) {
super(initParams);
sortMapping.put("date", "title"); // no date field on wikipedia results
sortMapping.put("relevancy", "_score");
sortMapping.put("title", "title");
}
@Override
public Collection<SearchResult> search(SearchContext context, String query, Collection<String> sites, int offset, int limit, String sort, String order) {
Collection<SearchResult> results = new ArrayList<SearchResult>();
String esQuery = "{\n" +
" \"from\" : " + offset + ", \"size\" : " + limit + ",\n" +
" \"sort\" : [\n" +
" { \"" + sortMapping.get(sort) + "\" : {\"order\" : \"" + order + "\"}}\n" +
" ],\n" +
" \"query\": {\n" +
" \"filtered\" : {\n" +
" \"query\" : {\n" +
" \"query_string\" : {\n" +
" \"query\" : \"" + query + "\"\n" +
" }\n" +
" }\n" +
" }\n" +
" },\n" +
" \"highlight\" : {\n" +
" \"fields\" : {\n" +
" \"text\" : {\"fragment_size\" : 150, \"number_of_fragments\" : 3}\n" +
" }\n" +
" }\n" +
"}";
try {
HttpClient client = new DefaultHttpClient();
HttpPost request = new HttpPost("http://localhost:9200/_search");
StringEntity input = new StringEntity(esQuery);
request.setEntity(input);
HttpResponse response = client.execute(request);
StringWriter writer = new StringWriter();
IOUtils.copy(response.getEntity().getContent(), writer, "UTF-8");
String jsonResponse = writer.toString();
JSONParser parser = new JSONParser();
Map json = (Map)parser.parse(jsonResponse);
JSONObject jsonResult = (JSONObject) json.get("hits");
JSONArray jsonHits = (JSONArray) jsonResult.get("hits");
for(Object jsonHit : jsonHits) {
JSONObject hitSource = (JSONObject) ((JSONObject) jsonHit).get("_source");
String title = (String) hitSource.get("title");
JSONObject hitHighlights = (JSONObject) ((JSONObject) jsonHit).get("highlight");
JSONArray hitHighlightsTexts = (JSONArray) hitHighlights.get("text");
String text = "";
for(Object hitHighlightsText : hitHighlightsTexts) {
text += (String) hitHighlightsText + " ... ";
}
results.add(new SearchResult(
"http://wikipedia.org",
title,
text,
"",
"http://upload.wikimedia.org/wikipedia/commons/thumb/7/77/Wikipedia_svg_logo.svg/45px-Wikipedia_svg_logo.svg.png",
new Date().getTime(),
1
));
}
} catch (Exception e) {
e.printStackTrace();
}
return results;
}
}Requests and responses are full JSON. You can find more details about ElasticSearch query syntax here. The important point about the search connector is that each result has to be a SearchResult object returned in a collection.
Deploy your jar (which contains the SearchConnector class and the XML configuration file) in the libs of the application server (/lib of Tomcat for example), then start eXo Platform.
In the quick search from the Administration bar, the Wikipedia content will be retrieved:
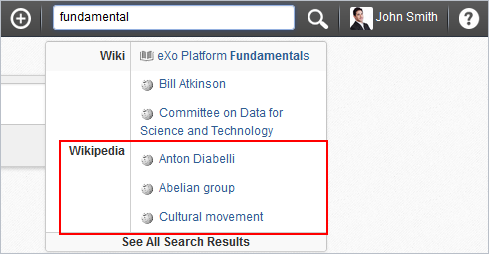
In the Search page, the Wikipedia filter will be listed with some Wikipedia pages as search results:
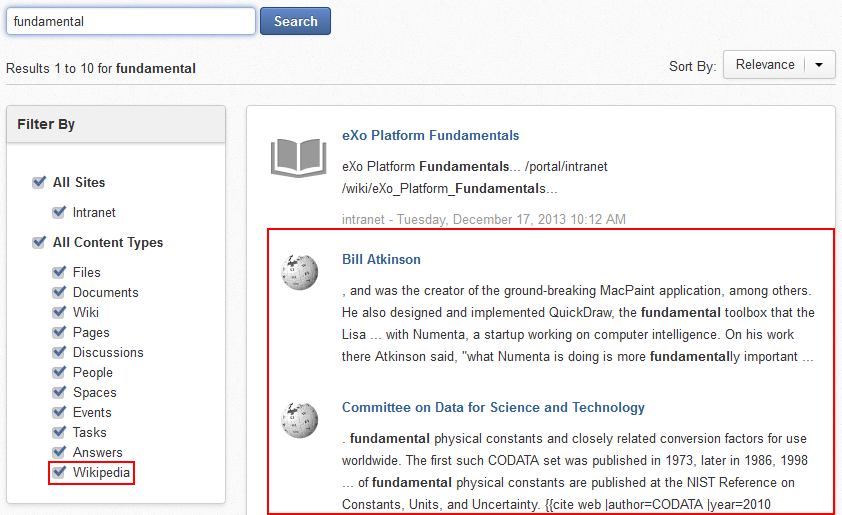
If you want to exclude Wikipedia content from the search results, simply uncheck the Wikipedia filter:
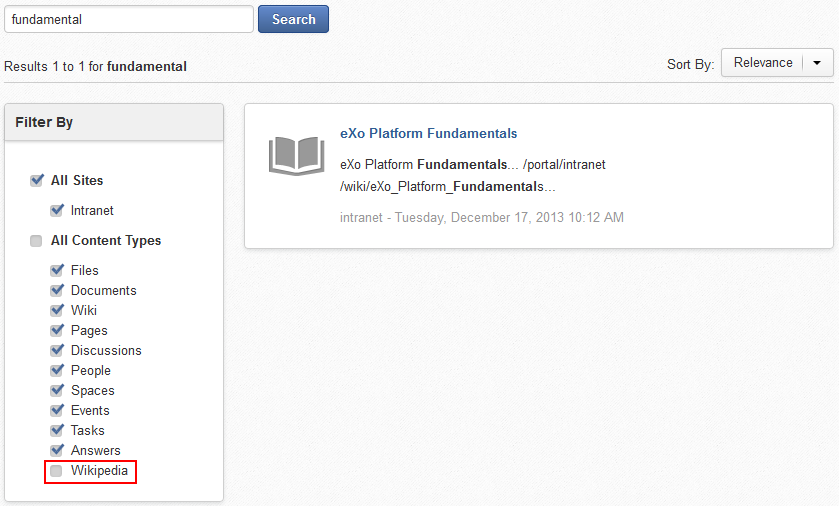
Note
You can see the code sources here, as a Maven project.