Warning
You are looking at documentation for an older release. Not what you want? See the current release documentation.
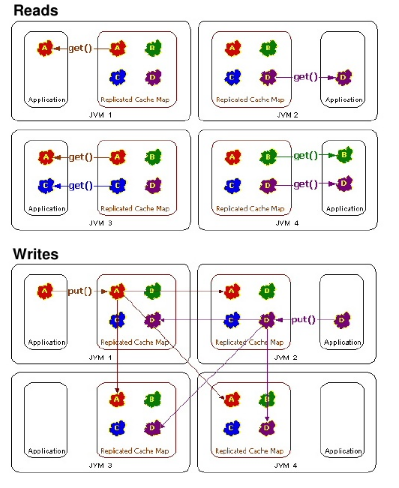
In a replicated cache all nodes in a cluster hold all keys i.e. if a key exists on one node, it will also exist on all other nodes. A replicated cache does not partition data, instead, it replicates the data to all nodes.
Replicated mode can be synchronous or asynchronous. Synchronous replication blocks the caller (e.g. on a cache.put(key, value)) until the modifications have been replicated successfully to all the nodes in the cluster. Asynchronous replication performs replication in the background, and write operations return immediately. Asynchronous replication is not recommended, because communication errors, or errors that happen on remote nodes are not reported to the caller.
In case you have big values or non-serializable values and you need a replicated cache to at least invalidate the data when it is needed, you can use the invalidation mode that will work on top of any replicated cache implementations. This is possible thanks to the class org.exoplatform.services.cache.invalidation.InvalidationExoCache which is actually a decorator whose idea is to replicate the hash code of the value in order to know if it is needed or not to invalidate the local data. If the new hash code of the value is the same as the old value, we don't invalidate the old value. This is required to avoid the following infinite loop that we will face with invalidation mode proposed out of the box by JBoss Cache, as in the following example:
Cluster node #1 puts (key1, value1) into the cache.
On cluster node #2 key1 is invalidated by put call in node. #1
Node #2 re-loads key1 and puts (key1, value1) into the cache.
On cluster node #1 key1 is invalidated, so we get back to step #1.
In the use case above, thanks to the InvalidationExoCache, since the value loaded at step 3 has the same hash code as the value loaded as step 1, the step 4 will not invalidate the data on the cluster node #1.
Invalidation mode can be synchronous or asynchronous. When synchronous, a write blocks until all nodes in the cluster have evicted the stale value. When asynchronous, the originator broadcasts invalidation messages but doesn’t wait for responses. That means other nodes still see the stale value for a while after the write completed on the originator.

There are 2 ways to use the invalidation mode:
By configuration: simply set the parameter
cacheModeto syncInvalidation or asyncInvalidationin your eXo Cache configuration.Programmatically: You can wrap your eXo cache instance in an InvalidationExoCache (for synchronous invalidation) or AsyncInvalidationExoCache (for asynchronous invalidation) using the available public constructors. You can wrap your eXo cache instance in an InvalidationExoCache yourself using the available public constructors.
Note
The invalidation will be efficient if and only if the hash code method is properly implemented, in other words 2 value objects representing the same data need to return the same hash code otherwise the infinite loop described above will still happen.
Advantages/disadvantages of each cache mode
| Cache strategy | Advantage | Disadvantage | Recommended use case |
|---|---|---|---|
| Synchronous replication | All remote data updated instantly | Blocked put/remove operation on cluster | Shared logic data : group data + portal data + public data. Instantly changes required. |
| Asynchronous replication | Put/remove operation is more performed.Do not wait for update remote cluster nodes. | Remote cache data is not up to date instantly. Risk of failed replicated data. | Shared logic data : group data + portal data + public data. |
| Synchronous Invalidation | Remote data invalidate instantly.Reduce sent/recive jgroups bytes.Reduce cahce size. | Blocked put/remove operation on cluster. Cost of access databases. | User data, Big Object, List data,instantly changed required. |
| Asynchronous Invalidation | Reduce sent/recive jgroups bytes.Reduce cahce size | Remote cache data is not invalidate instantly. Risk of failed invalidate data. Cost of access databases. | User data, Big Object, List data. |
If the data that you want to store into your eXo Cache instance takes a lot of time to load and/or you would like to prevent multiple concurrent loading of the same data, you can use org.exoplatform.services.cache.future.FutureExoCache on top of your eXo Cache instance in order to delegate the loading of your data to a loader that will be called only once whatever the total number of concurrent threads looking for it. See below an example of how the FutureExoCache can be used:
import org.exoplatform.services.cache.future.Loader;
import org.exoplatform.services.cache.future.FutureExoCache;
...
// Define first your loader and choose properly your context object in order
// to be able to reuse the same loader for different FutureExoCache instances
Loader<String, String, String> loader = new Loader<String, String, String>()
{
public String retrieve(String context, String key) throws Exception
{
return "Value loaded thanks to the key = '" + key + "' and the context = '" + context + "'";
}
};
// Create your FutureExoCache from your eXo cache instance and your loader
FutureExoCache<String, String, String> myFutureExoCache = new FutureExoCache<String, String, String>(loader, myExoCache);
// Get your data from your future cache instance
System.out.println(myFutureExoCache.get("my context", "foo"));