This chapter provides developers with the reference knowledge for using and developing JCR via two main topics:
Issues around how to use JCR, NodeType, Namespace, Searching repository content, and Fulltext search.
Details of advanced usages in JCR, including Extensions, Workspace data container, Binary values processing, and Link producer service.
The main purpose of content repository is to maintain the data. The heart of content repository is the data model:
The main data storage abstraction of JCR's data model is a workspace.
Each repository should have one or more workspaces.
The content is stored in a workspace as a hierarchy of items.
Each workspace has its own hierarchy of items.
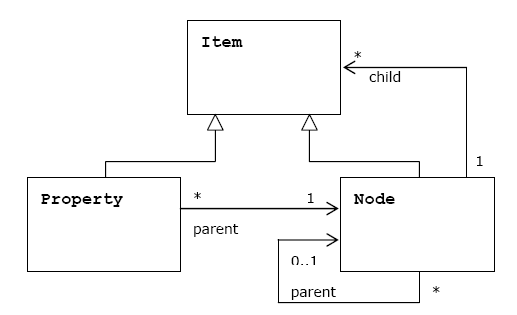
Node is intended to support the data hierarchy. It is of type using namespaced names which allow the content to be structured in accordance with standardized constraints. A node may be versioned through an associated version graph (optional).
Property stored data are values of predefined types (String, Binary, Long, Boolean, Double, Date, Reference, Path).
Note
The data model for the interface (repository model) is rarely the same as the data models used by the repository's underlying storage subsystems. The repository knows how to make the client's changes persistent because that is a part of the repository configuration, rather than part of the application programming task.